交换机故障导致线程阻塞
文章目录
本来使用工具或者服务
- Jconsole
- Jstack
- prometheus
架构图
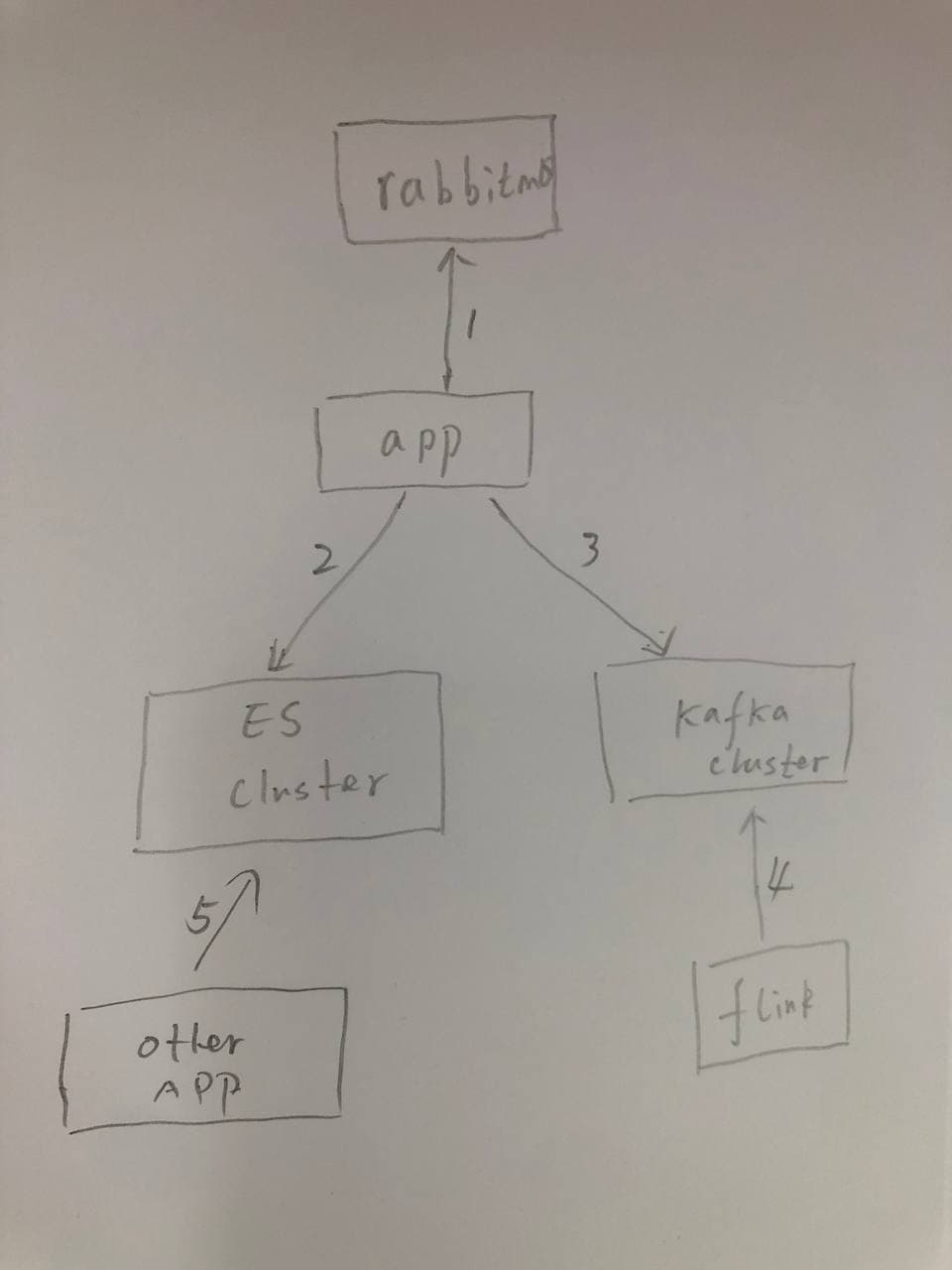
架构说明
-
This is an internal application (Not cloud) architect,we have big network traffic and lots of application ,we deploy in our own server
-
we have a RabbitMQ server (which our data provider will send HKEX data to this server)
-
we have an Application will consume the messages from MQ
-
Our application will process the data and sending to Kafka and Elastic search
-
Our Flink (Data process Framework) will process the data (Calculate) TO generate quantitative data to anthoer Kafka topic
-
We have a transaction appliction to consume the KAfka Topic data to trade equities or derivatives
Issue
- 我们看到我们交易程序没有下任何单,我们认为我们程序出现了信号,但是交易程序并没有下单记录,也就是说信号没有出现,我们flink并没有计算出信号
Diagnose
-
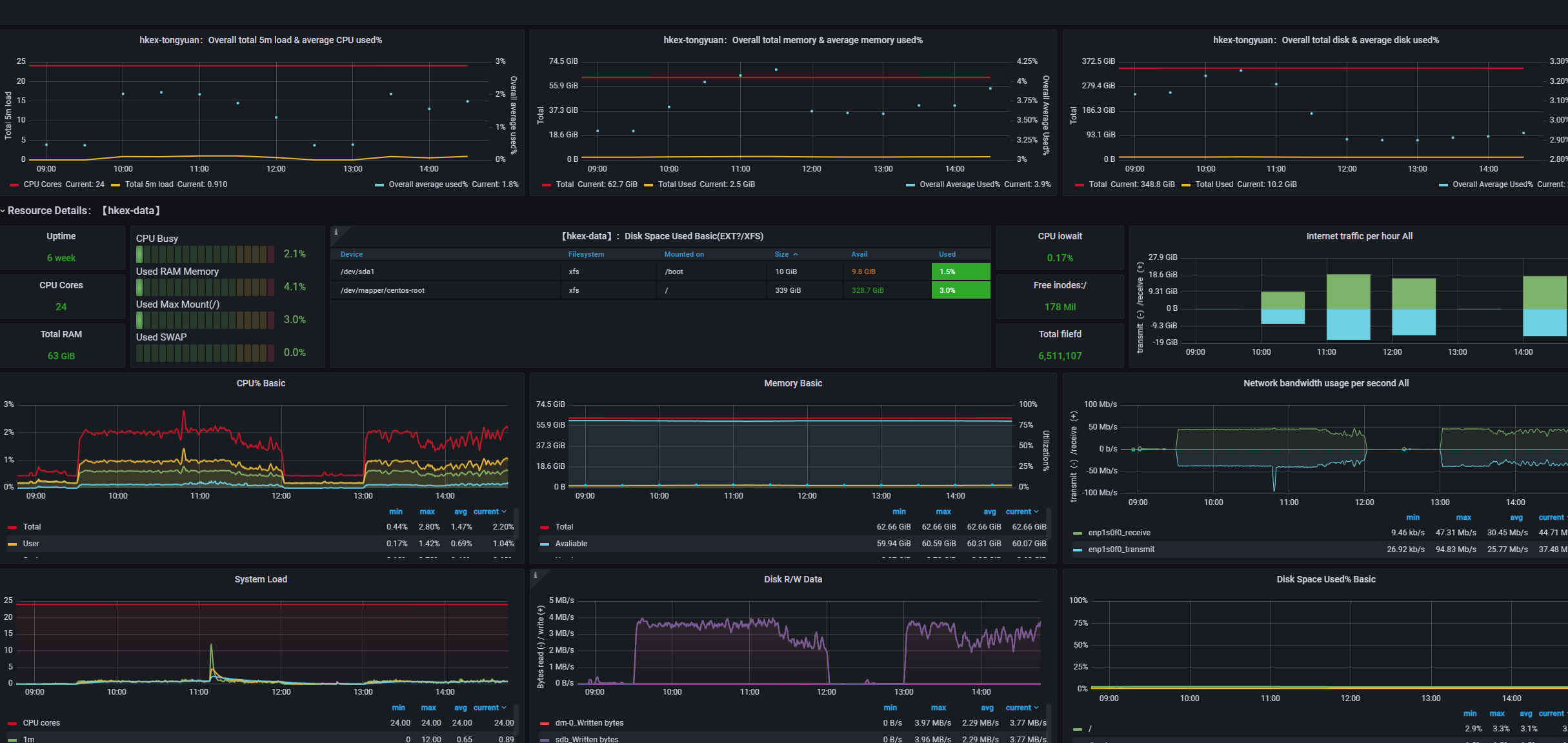
由于我已经在各个服务安装了nodeexporter,把数据集中发送到prometheus上,所以我们用prometheus来监控各个主机内存网络硬盘cpu等状态,没有发现任何问题
-
rabbitmq每秒接受到45M的数据,经过计算后传输出去的数据大概是40M/s。
-
我排查了数据供应商发送的rabbitmq的消息,新创建了一个测试queue,绑定了trade和quote的数据,检查timestamp发现并没有出现数据延迟
-
排查我们的kafka的MQ,发现我们加工完数据后,生在kafka里面后延迟了几十秒,多的长达几十分钟!!!
-
所以必须是我们 application处理数据的时候出了问题,检查app server ,系统负载,disc io ,内存,cpu,文件句柄数,都在正常范围内
-
检查JVM,用jstack dump出堆栈数据,发现一堆线程处于waiting状态,32核cpu总体利用率很低,跟踪类,发现kafka很多org.springframework.kafka.kafkalistenerendpointcontainer blocked 这肯定写入kafka出现了问题,然后各种优化调试都不起作用!
-
绝望的时候检查了网络,突然发现从application ping到kafka需要100ms!从其他服务器ping到application都需要100ms,也就是延迟由于网络的原因导致线程池暴涨!
-
经过检查发现application这台服务器所在交换机出现了故障,换了交换机之后,一切恢复正常,单次kafka的发送1ms以下
Summary
- 在应用中缺乏网络可靠性的检测工具
- 如果不是使用云平台的话,很多硬件的监控完全需要团队自己搭建,这样的成本会提高很多,如果在云平台的话,他们的硬件的availability都是很高的,这样的问题不会发生